
The Triveritas Stress Test
AI Models Can’t Evaluate Their Own Work. Here’s a Framework That Uses Their Blind Spots Against Each Other.


If you’ve read Vox Day’s Veriphysics or seen his recent Triveritas analysis of the “Judaism is the foundation of the free world” claim, you know what the Triveritas does to a truth claim when applied rigorously: it breaks the claim into three independently testable dimensions and checks whether any of them hold.
This post asks a different question: can AI models run that test for you? And if so, which models are good at which legs — and how do you prevent them from all making the same mistakes?
The answer is yes, with caveats. This is Part I: the framework. Part II will test it empirically.
The Bottleneck Has Moved
AI does not make writers smarter. It reduces cognitive friction, allowing writers to sustain their best analytical work across longer and more formal outputs. This is Jordamøn’s observation about coding tools — that software development was once constrained by how fast humans could type and how much complexity they could hold in their heads, and that AI has largely removed the first constraint — applied to analytical writing (Jordamøn, “The New Bottleneck,” AI Central).
The consequence is the same in both domains. When production becomes easy, evaluation becomes the binding constraint. The 2025 DORA report found that AI amplifies existing engineering quality rather than creating it: strong teams become more productive while weak teams produce more buggy code faster. The analytical writing equivalent is that a writer with genuine domain expertise and strong reasoning produces better work faster with AI assistance, while a writer without those qualities produces more polished nonsense at greater speed.
The question, then, is not which AI model writes best. It is which combination of models evaluates best — and specifically, which models are good at catching which kinds of failure.
The Triveritas as an Evaluation Framework
Vox Day’s Veriphysics: The Treatise (Castalia House, 2024) introduces the Triveritas — the Triad of Truth — as an epistemological criterion. A claim merits assent when and only when it satisfies three conditions: logical validity, mathematical coherence, and empirical anchoring. Each condition is necessary; none is sufficient; the conjunction of all three is required.
The Triveritas was developed as a philosophical tool for evaluating knowledge claims. It also provides a useful framework for adversarial review of analytical writing, because each leg tests something different and each can be approached from a different angle. The writer who drafts with AI assistance needs reviewers who can check all three legs. No single model checks all three well. The question is which models are strongest on which legs, and — critically — which stress-test task exploits that strength most effectively.
Two clarifications at the outset. First, the three legs are not hermetically sealed compartments. A strong counterargument inevitably requires awareness of empirical gaps; deriving calculations from first principles requires understanding the logical structure those numbers serve; identifying falsifiable empirical claims requires both logic and quantitative reasoning to know what actually bears weight. The legs are entry points — angles of attack that bias a reviewer’s attention toward one dimension of an argument without prohibiting it from noticing failures on the others.
Second, the mathematical coherence leg does not require every analytical piece to contain equations. It requires that where quantitative reasoning is possible — where an argument makes claims about rates, magnitudes, probabilities, or timescales — that reasoning has been made explicit and survives scrutiny. A signal detection analysis of AI rater models began as an attempt to replicate a claim about AI-assisted cognitive enhancement. The replication failed, but the scoring data, subjected to ROC analysis with AUC and d-prime, revealed something the models could not see about themselves (keruru, “The Model That Can’t See Itself”). That is Leg 2 working practically: not competition mathematics, but the discipline of making the implicit quantitative structure of an argument explicit and checking whether it holds.
Why Not One Model?
The research on LLM error correlation answers this directly. Kim et al. (2025), in a large-scale empirical study of over 350 LLMs presented at ICML, found that when two models both make errors on the same benchmark items, they agree on approximately 60% of those errors — that is, conditioned on both models failing, the probability that they fail in the same way is roughly 0.6. Models from the same provider show higher error correlation. And — the finding that matters most — larger, more capable models have more highly correlated errors, even across distinct architectures and providers.
A separate information-theoretic analysis of LLM ensemble selection (2025) formalised the point: models from the same family share training data, architectures, and failure modes, so adding another high-accuracy model from the same family may contribute little new information or may even reinforce the same mistakes.
This has been empirically demonstrated in the specific context of AI-assisted writing evaluation. A signal detection analysis applying ROC curves, AUC, and d-prime to three AI rater models (Grok 3, DeepSeek R1, and GPT-4o) evaluating a naturalistic writing corpus found dramatically different detection and scoring profiles across models (keruru, 2026; technical paper). The study is an exploratory case study — two authors, 24 texts, three rater models — and should be read as preliminary observation rather than established finding. No statistical inference is reported; the sample size supports pattern identification, not generalisation. But the pattern it documents is striking:
Signal Detection Performance by Model (keruru, 2026)
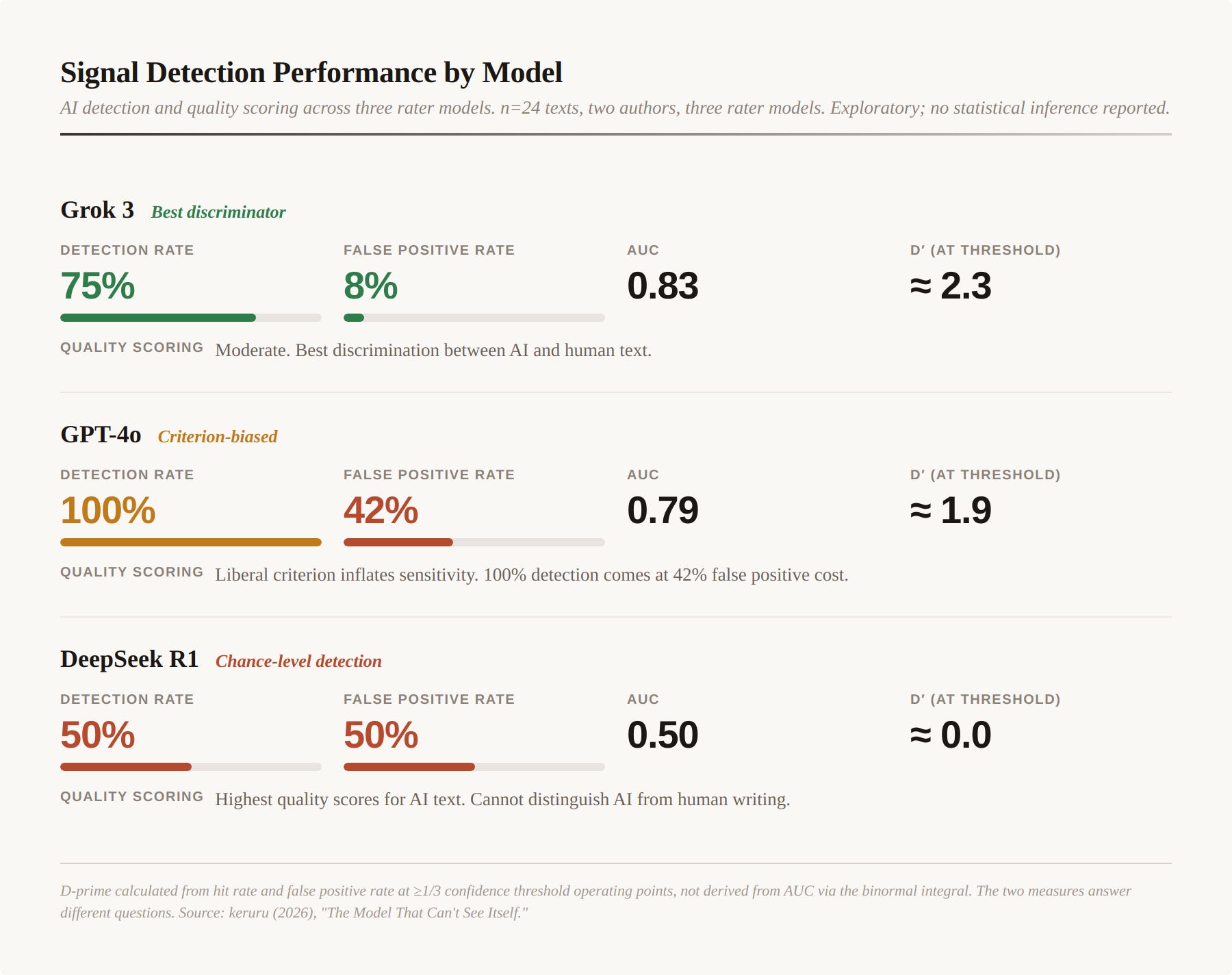
n=24 texts, two authors, three rater models. Exploratory; no statistical inference reported. D-prime calculated from hit rate and false positive rate at ≥1/3 confidence threshold operating points, not derived from AUC via the binormal integral. The two measures answer different questions.
DeepSeek R1 assigned the highest quality scores to AI-assisted scientific writing while performing at literal chance on AI detection. Grok 3 achieved the best discriminative performance. GPT-4o achieved 100% detection but at a 42% false positive rate — high sensitivity driven by a liberal criterion rather than genuine discrimination.
The implication: a single-model review workflow will miss failures that a multi-model workflow catches, because different models are blind in different places. But the models must be chosen for uncorrelated blind spots, not just different brand names. A single generalist model running all three Triveritas checks in one pass will produce errors correlated across all three legs — the concordance problem applies within a model as much as between models.
Evidence From Practice
The keruru signal detection paper was itself developed through multi-model adversarial review — four rounds of stress-testing across Grok, GPT-4o, DeepSeek, and Claude, with an iteratively improving review prompt. The results illustrate the practical case for cross-model evaluation.
Grok correctly identified a sensitivity miscount (4/12 = 33% at the ≥2/3 threshold, not 3/12 = 25%) that GPT-4o and DeepSeek both missed — both confirmed the incorrect figure. GPT-4o identified the “autobiographical demonstration” framing and the three-way directionality problem (AI caused genre shift / genre shift alone explains scores / both contribute independently). DeepSeek — reviewing a paper about its own behaviour — produced the most rigorous CHC validity critique and correctly identified Grok as the best discriminator by standard signal detection metrics. Claude synthesised the reviews and identified where the models disagreed with each other.
No single model found everything. Each found things the others missed. Two models confirmed the wrong number for the same statistic. The cross-model workflow caught an error that would have persisted through any single-model review, because the error was subtle enough that two out of three reviewers accepted it.
This is not a controlled experiment. It is a worked example of the proposed workflow applied to a real analytical document. Part II will test the framework more systematically.
What This Replaces
Consider what the current evaluation process for analytical writing actually looks like, particularly in academic publishing. You write the paper. You check it. You swap it between co-authors. The best English writer submits it. It is rejected. You use the peer review — which may have taken months to arrive and may reflect the reviewer’s institutional commitments more than the paper’s analytical quality — to modify the manuscript. It becomes more cautious, more hedged, more boring. After several iterations it is accepted in a lesser-impact journal, and the interesting analytical moves that motivated the work are no longer there. The process optimises for inoffensiveness rather than truth. It is, in the precise sense of the word, baroque.
How slow is this process? Björk & Solomon (2013), in a study of 2,700 papers across 135 journals sampled from Scopus, found average delays from submission to publication ranging from 9 months in chemistry to 18 months in business and economics — with the largest source of variance being between articles within a single journal, not between disciplines. A 2025 study of 57 health policy journals found that the complete publication process ranged from 35 to 353 days, with median time to final peer-reviewed decision at 198 days — over six months. A survey of conservation biology authors found typical peer review turnaround of 14 weeks, with the longest reported review times averaging 31 weeks. Publication lag — the additional delay between acceptance and print appearance — adds further months; Heneberg (2013) found cumulative publication lag reaching years in some dual-format journals, with mean per-manuscript delays of 0.3 to 1.3 years between online availability and assignment to a print issue.
The delay is not the only cost. Franco, Malhotra & Simonovits (2014) analysed 221 studies from the TESS archive — a known population of conducted experiments — and found that strong results were 40 percentage points more likely to be published than null results, and 60 percentage points more likely to be written up at all. The peer review process does not merely take months; it systematically suppresses findings that fail to reach significance, regardless of their validity. The Triveritas stress test has no such bias — it tests whether the argument holds, not whether the results are exciting.
The Triveritas stress test is three conversations and a human review. It tests whether the argument holds rather than whether it pleases reviewers. It is adversarial by design — each model is asked to attack the argument from a specific angle rather than evaluate it sympathetically. And it produces actionable feedback: here is where your logic fails, here is where your numbers don’t survive, here is where your empirical anchoring is missing. The writer can address these failures in the next draft rather than waiting months for a reviewer who may not have read past the abstract.
This is not to claim that the Triveritas stress test is a proven replacement for peer review. It is a hypothesis — a testable proposal that multi-model adversarial review, structured around the three legs of the Triveritas, produces faster and more useful feedback on analytical writing than existing alternatives. Part II will test that hypothesis empirically. But the comparison baseline is not some idealised process of disinterested scholarly evaluation. It is the actual process, which anyone who has published academically knows is slow, capricious, and frequently captures the standard in exactly the way that keruru’s analysis of professional licensing examinations describes (keruru, “Who Owns the Standard?”).
The Current Landscape: Models People Actually Use
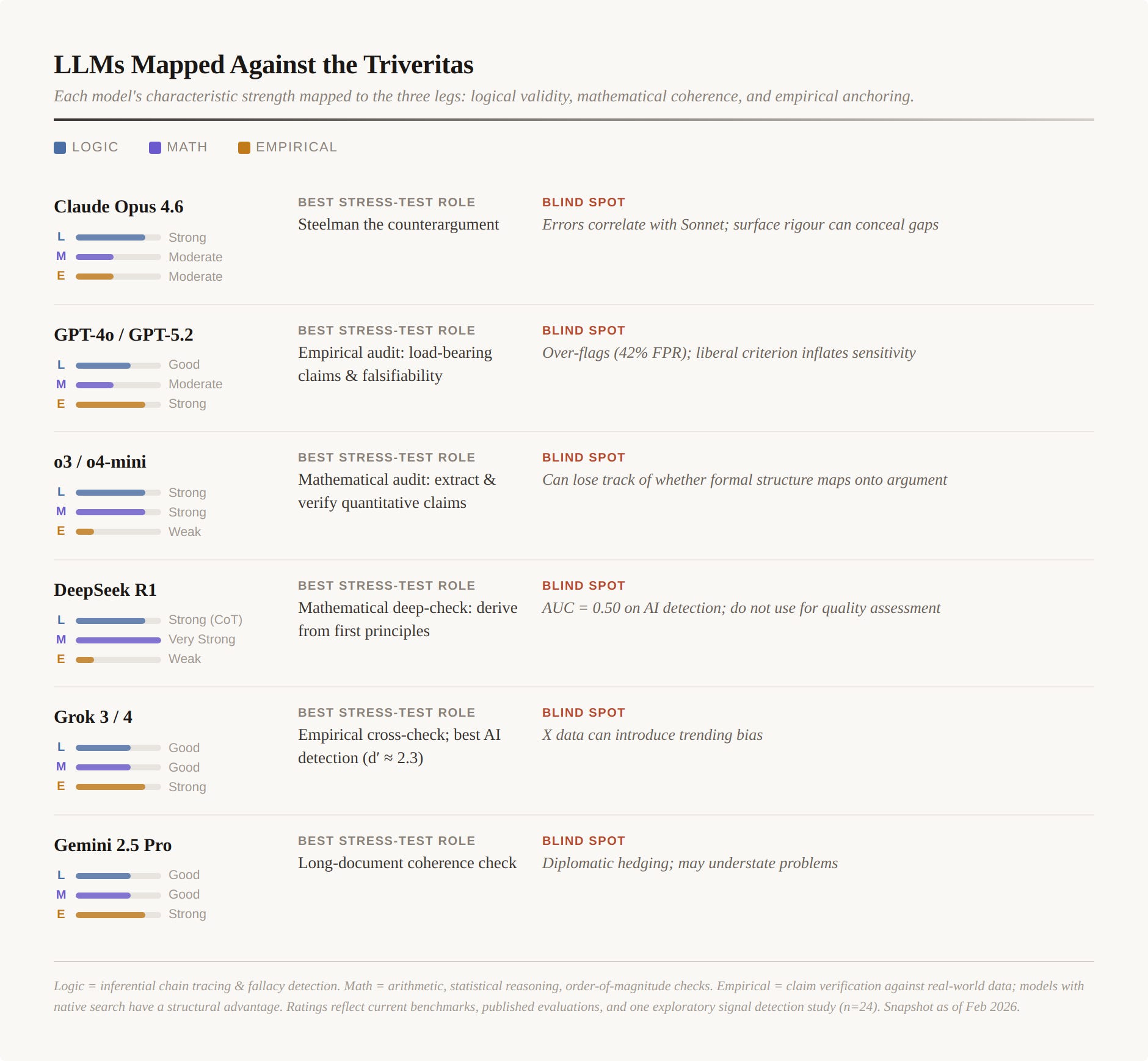
The table below covers models that are currently shipping, widely available, and used in real workflows. For each model, the assessment covers its characteristic strength and weakness against each leg of the Triveritas, and recommends a specific stress-test task that exploits that strength.
A caveat: these ratings reflect current benchmark data, published evaluations, and one exploratory signal detection study (n=24 texts, two authors, three rater models). They are not derived from systematic testing against the Triveritas legs specifically — that is what Part II will do. Frontier models evolve in weeks; the table is a snapshot, not a permanent mapping. The structural recommendation (use different models for different legs, with structurally different tasks) should survive model updates even if the specific ratings shift.
Current LLMs Mapped Against the Triveritas
The Stress-Test Tasks
The most common mistake in multi-model review is asking every model the same question: “Review this piece and identify any errors.” This produces the concordance problem — models converge on the same assessment because they evaluate similar surface features using similar trained intuitions. Even cross-provider models agree on errors 60% of the time.
The Triveritas framework addresses this by assigning each model a structurally different task matched to the leg it approaches most effectively. The tasks are entry points, not silos — a model working on Leg 1 may well notice Leg 2 or Leg 3 failures, and should report them. But the task design biases attention toward one dimension of the argument, which reduces the probability that all three reviewers converge on the same superficial assessment.
Leg 1 — Logical Validity. The task is not “check the logic” but “construct the strongest counterargument.” This forces the model to work against the argument rather than evaluate it, surfacing logical weaknesses that a sympathetic reading would miss. The steelmanned counterargument reveals which premises are load-bearing and which inferences are weakest. Best entry-point models: Opus 4.6, o3, DeepSeek R1’s chain-of-thought mode, Grok 4 (multi-engine).
Leg 2 — Mathematical Coherence. The task is not “check the numbers” but “derive the calculations from first principles.” Many analytical arguments contain implicit quantitative claims — rates, magnitudes, probabilities, timescales — that are never made explicit. Forcing a model to extract these and calculate independently reveals whether the numbers support the argument or have been assumed. This is the Wistar Institute move that Day identifies in Veriphysics: make the math do the work. Where a piece contains no quantitative claims, Leg 2 is satisfied vacuously — but the reviewer should note whether quantitative reasoning could have been applied and wasn’t, which is itself a form of failure on this leg. Best entry-point models: DeepSeek R1, o3/o4-mini.
Leg 3 — Empirical Anchoring. The task is not “verify the facts” but “identify the load-bearing empirical claims and specify what would falsify them.” This forces the model to distinguish between decorative citations and claims the argument depends on, and to identify whether the evidence base is real or circular. Best entry-point models: Grok 3/4 (with DeepSearch), GPT-4o/5.2 (with browsing), Gemini 2.5 Pro (with Google Search).
Practical Workflow
For a serious analytical piece — the kind that takes days or weeks rather than hours:
Draft with your preferred model. Sonnet, GPT-4o, or whatever reduces your cognitive friction most effectively.
Leg 1 stress-test (Logic): Send the completed draft to a cross-provider model strong on inferential reasoning with the steelman-counterargument task. Review the counterargument for genuine weaknesses.
Leg 2 stress-test (Math): Send any sections with quantitative claims to a model strong on mathematical reasoning with the derive-from-first-principles task. If there are no quantitative claims, ask whether there should be.
Leg 3 stress-test (Empirical): Send the draft to a model with web search access with the identify-and-falsify task. Check whether the empirical anchoring holds against current data.
Human final gate: Review all three stress-test outputs. The writer’s domain expertise is the check on errors all the models share.
Three conversations and a review. The feedback is specific and actionable. It tests whether the argument is true rather than whether it is acceptable.
What This Does Not Solve
This workflow addresses the evaluation bottleneck for analytical writing. It does not solve the production problem (which AI has already largely solved for writers with genuine expertise) or the dissemination problem (which is a different kind of institutional challenge).
It also does not claim to be validated. Part I is a hypothesis: that multi-model adversarial review structured around the Triveritas produces better evaluation of analytical writing than current alternatives. Part II will test this by selecting position pieces that vary in which Triveritas legs they satisfy, independently coding them against the framework, and then running them through the models to measure whether the stress tests detect what they should detect.
The signal detection data suggests that AI assistance reliably inflates stylistic markers without reliably fixing underlying reasoning — one AI-assisted text scored low because DeepSeek caught technical errors the AI had polished around but not corrected. A writer with a measured IQ of 170 (standardised instrument, administered independently of this study) had his unassisted blog posts scored at 99–103 on DeepSeek’s quality rubric — population average — while his AI-assisted scientific preprints scored 152–161. The 62-point gap reflects genre register and stylistic density, not cognitive capacity. The instrument measures what AI is good at producing, not what the writer is good at thinking.
The Triveritas stress test is designed for writers who use AI to reduce cognitive friction while maintaining genuine analytical control. For writers who use AI as a substitute for thinking, no stress-testing workflow will help, because there is nothing underneath the polish to evaluate. This is the DORA finding restated: AI amplifies existing analytical quality. It does not create it.
Appendix: This Paper as Pilot Test
Part I was itself developed through the Triveritas stress-test workflow it proposes. This appendix documents the process — not as validation (n=1 is not validation) but as a worked example of the framework in practice, including what it caught, what it missed, and what the results suggest about the method’s strengths and limitations.
The drafting process. The initial draft was produced in Claude Opus 4.6 (Sonnet-assisted), working from source material including the DORA report, Kim et al., the keruru signal detection paper, and Veriphysics. The draft went through four versions over the course of a single working session, with each version revised in response to a stress-test round.
Leg 1: Logical Validity (Grok 4.2, multi-engine). Grok 4.2 was given the steelman-counterargument task. It identified four critical weaknesses.
The most damaging was the leg separability problem: the draft described the three legs as if they could be tested in isolation, but a strong counterargument inevitably requires empirical and mathematical awareness. The draft was revised to reframe the legs explicitly as entry points that bias attention rather than hermetic compartments.
Grok also identified the unstated empirical claim — that the integrated workflow beats simpler alternatives — and correctly noted that Part I offered no comparative data. The draft was revised to frame Part I explicitly as a testable hypothesis, not a finding.
Third, the math-logic distinction for non-STEM writing: many analytical pieces have no quantitative claims, making the math leg vacuous. The draft was revised to address this directly.
Fourth, the simpler alternative challenge: could one strong generalist model with search plus human review achieve most of the benefit? The draft was revised to note that the multi-model workflow is justified when stakes and complexity warrant it.
Grok also applied the Triveritas to the Triveritas: it found the framework logically valid, mathematically coherent (vacuously — few quantitative claims in Part I itself), and partially empirically anchored — strong on problem diagnosis, weaker on solution validation.
Leg 2: Mathematical Coherence (DeepSeek R1). DeepSeek was given the derive-from-first-principles task. Its principal finding was an apparent inconsistency in the signal detection metrics: under the standard equal-variance binormal model, AUC = 0.83 for Grok 3 implies d′ ≈ 1.38, not the ≈ 2.3 reported. The resolution is that the keruru paper calculated d-prime from specific threshold operating points (hit rate and false positive rate at the ≥1/3 confidence threshold), not derived from AUC via the binormal integral. The two measures answer different questions. The draft was revised to make this derivation explicit, and the signal detection table was added to present the data directly rather than asserting numbers without context.
DeepSeek also correctly noted missing confidence intervals and the absence of the hit rate alongside the reported 8% FPR — valid presentation complaints for a study that explicitly identifies itself as exploratory (n=24, two authors). The draft’s sample size caveat was made more prominent.
What DeepSeek missed: it did not check whether the DORA “amplifier” claim has quantitative backing, and did not ask whether the 60% error agreement figure actually supports the strength of claim being made about cross-provider improvement.
Leg 3: Empirical Anchoring (GPT-5.2 with browsing). GPT-5.2 was given the identify-and-falsify task. It identified 19 load-bearing empirical claims in the draft and found that none were directly evidenced within the document itself — all were either cited externally without excerpt, described narratively without evidence, or asserted without citation.
The most consequential findings: the signal detection metrics were asserted numerically but not demonstrated (addressed by adding the table). The academic publishing timeline claim (”months to years”) was unsupported (addressed by adding the Björk & Solomon, Phillips & Horn, Nguyen, and Heneberg citations). The IQ/scoring claim was identified as the strongest falsifiable claim in the document with zero internal evidence (addressed by adding the standardised instrument parenthetical).
GPT-5.2’s meta-finding was the most important: “If this were stress-tested under its own rules, it would currently fail Leg 3 — not because the claims are false, but because the evidence is not presented inside the argument.” That observation motivated this appendix.
What the pilot test demonstrates. The stress-test process for Part I was completed within a single working session. Each leg produced actionable findings that improved the document. The legs found different things: Grok attacked the logical structure, DeepSeek caught a measurement derivation issue, GPT-5.2 audited the empirical anchoring systematically. No single model found everything. The human author (working with Claude as synthesiser) made final decisions about which findings to accept, which to reject, and how to revise.
What the pilot test does not demonstrate is comparative superiority. We do not know whether a single strong model running all three tasks in one pass would have caught fewer errors, or different errors, or the same errors. We do not know whether the sequential structure (Leg 1 → Leg 2 → Leg 3) introduced ordering effects. These are empirical questions for Part II.
What it does demonstrate is that the workflow is executable — that it produces specific, falsifiable criticism of a real document in a timeframe measured in hours, and that different models assigned to structurally different tasks find different failures. Whether it produces better criticism than alternatives remains to be tested.
Part II will select position pieces that vary in which Triveritas legs they satisfy, independently code them against the framework, then run them through the models using the leg-specific tasks described above to measure whether the models’ assessments correlate with human judgment, with each other, and whether cross-model disagreement is informative or noise.